El SPI (Sistema de Pagos Instantáneos) del Paraguay es una red de pagos instantáneos del Banco Central del Paraguay (en adelante, BCP) que permite a todos los clientes de bancos y financieras reguladas por el ente del estado, hagan transferencias instantáneas, validadas en origen y en destino, con confirmación inmediata, durante las 24 horas de los 7 días de la semana.
Desde el año 2004, trabajamos muy de cerca con todo el sector financiero en el desarrollo de sus canales digitales, por lo que nos pareció natural para nuestros clientes actuales, y potenciales nuevos clientes, proponer una solución que permita, con la menor cantidad de cambios posibles, poder integrar los CORES FINANCIEROS de cada uno, con el protocolo propuesto desde el BCP. Así nació la idea de XAIX en Agosto de 2021.
No hubo mucho debate ni análisis sobre el nombre. Tenemos un sistema al que llamamos internamente
XAI que sirve para conectar entidades financieras al
SIPAP. Como se puede considerar que el SPI es un complemento o extensión del
SIPAP, nos hizo sentido que el sistema para conectar entidades financieras al SPI se llame
XAIX (XAI - extended).
La mensajería de este protocolo está basada en el estándar ISO-20022 usando como transporte, un intercambio de mensajes firmados digitalmente por los participantes (bancos y financieras) a través de colas manejadas por un REST API (tanto para escritura como para lectura) alojado en el BCP.
Identificamos 5 (cinco) desafíos fundamentales para el proyecto:
1. Conseguir clientes
Necesitábamos por lo menos a 3 clientes que adopten nuestra solución para que el esfuerzo y el compromiso de cumplir con los estrictos plazos del BCP valgan la pena.
Armamos una linda presentación, sin tener aun las especificaciones técnicas del BCP (que a esa altura no existían) y se la hicimos a todos nuestros clientes, así como también a otras entidades financieras tratando de sumar adeptos. En esa presentación poníamos de manifiesto la arquitectura de la solución, el stack tecnológico, los requerimientos para desplegarla, la carga estimada que soportaba, así como también cómo iba a ser el proceso de integración con cada uno de los CORE FINANCIEROS.
Nuestra presentación cerraba así, por lo que estábamos muy confiados.
Recién en Diciembre nos confirmó el primer cliente. Grande. Pero solo era uno. Necesitábamos por lo menos dos más. La apuesta ya estaba hecha ya que el desarrollo ya estaba en marcha (no podíamos darnos el lujo de esperar las confirmaciones) y cada día que pasaba crecía la ansiedad. Igual, como lo que nos gusta es hacer Software, nos estábamos divirtiendo bastante con el desarrollo a esa altura, entonces eso hacía pasar un poco el nerviosismo.
En Enero 2022, empezaron a llegar las demás confirmaciones.
Finalmente, de los 3 que queríamos, terminamos aceptando trabajar con 10 (diez) entidades. Así que, cambiamos el nerviosismo de no tener las entidades mínimas necesarias, al nerviosismo de cómo hacer para manejar, en tan poco tiempo tantos procesos de desarrollo, con bases de datos distintas, con CORE FINANCIEROS distintos y con clientes con formas de trabajo bien distintas.
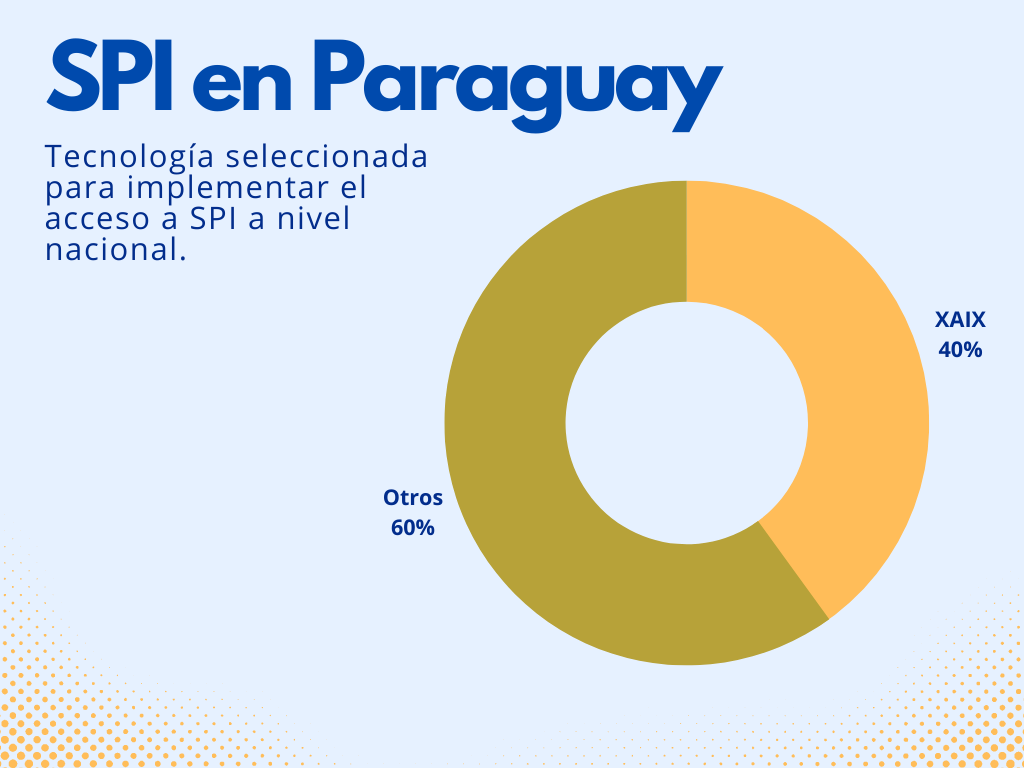
Hay 25 entidades en total que están sumadas al proyecto de SPI del BCP. Diez (40%) optaron por XAIX. Nada mal.
2. Armar el equipo
De las más de 180 personas que trabajan con nosotros, teníamos que conformar un equipo COMANDO que lleve adelante el proyecto, sin desatender los proyectos comprometidos que están en curso.
Parece fácil, pero no es. Los equipos de desarrollo de sistema sufren mucho las rotaciones de personas que tienen, entonces teníamos que elegir bien, sin romper los proyectos en curso.
Terminamos armando un equipo de 10 personas, divididos en tres sub equipos comando.
Equipo XAIX
Encargado de desarrollar el corazón de XAIX, que iba a ser común a las 10 implementaciones que teníamos.
Plugins de Integración
Encargado de interactuar con todos los clientes que iban a desarrollar la parte correspondiente al CORE FINANCIERO, para poder integrarlo al SPI a través de XAIX, desarrollando un microservicio al que llamamos plugin.
Despliegue
Encargado de desarrollar y definir con cada cliente la estrategia de despliegue en producción de acuerdo a la infraestructura de cada uno.
3. Diseñar una solución flexible y extensible
Cualquier solución que se tiene que integrar con a CORE FINANCIEROS diferentes, que tienen sistemas gestores de base de datos diferentes, tiene que ser extensible desde la concepción misma de la solución. Esta es la arquitectura de XAIX.
Tiene cuatro microservicios fundamentales:
XAIX SPIConnect
Se encarga de toda la comunicación con BCP, incluyendo la mensajería ISO-20022, y la firma digital criptográfica de los mensajes salientes y su correspondiente validación en los mensajes entrantes.
XAIX API
Se encarga de orquestar a todos los componentes, así como también de ser la única interfaz de entrada para darle instrucciones al XAIX a través de un API REST.
XAIX Plugin
Se encarga de comunicad de manera estandarizada a XAIX con los CORE FINANCIEROS de cada una de las 10 implementaciones. Estas son todas las alternativas que podíamos implementar en cada uno de los plugins para poder integrarnos a las soluciones de CORE FINANCIERO de los clientes.
XAIX WEB Admin
Administrador WEB para MONITOREO del estado general del sistema, así como también con las interfaces de usuario de administración para todo lo que tenga que ver con gestiones que se hacen en el BCP, así como también mantenimiento y configuraciones del XAIX. Los datos presentados en la captura de pantalla son ficticios, obviamente.
Para apreciar lo extensible y flexible de la solución, esto era lo que soportamos a nivel de tecnologías de bases de datos relacionales, en memoria y de tiempo (para estadísticas y monitoreo):
Y esto es lo que soportamos a nivel de despliegue:

Finalmente:
* De nuestras diez implementaciones 4 eligieron Oracle, 3 Microsoft SQL Server y 3 PostgreSQL.
* De nuestras diez implementaciones 3 desplegaron en un CLUSTER de K8S, 6 desplegaron en contenedores DOCKER usando Linux, y 1 desplegó usando un Servidor de Aplicaciones convencional.
* 4 usan nuestros APIs REST de manera síncrona y 6 usan nuestros APIs REST de manera asíncrona.
Todo usando exactamente la mismísima solución, donde lo único específico de cada implementación es el microservicio que contiene al PLUGIN de conexión.
Hablame de flexibilidad...
4. Diseñar una solución robusta y escalable
Esto era clave desde el día cero. El crecimiento de SIPAP, sobre todo en pandemia fue exponencial. Los números están a la vista la WEB del BCP. Por las características de los pagos, se calcula que el SPI va a manejar más del 90% de los pagos electrónicos bancarios del Paraguay en el modelo 365/7/24 (todos los días del año, sin concepto de días hábiles, 7 días a la semana durante 24 horas cada día). Por lo tanto, SPI tiene que ser escalable y, sobre todo, robusto.
Para esto, solo dependemos de un componente estratégico para administrar la comunicación interna de los microservicios que es la base de datos de alta performance en memoria REDIS. El sistema puede funcionar temporalmente sin base de datos de tiempo y sin base de datos relacional, pero no sin REDIS. Esta base de datos se puede instalar en un CLUSTER redundante para tener failover en caso de algún mal funcionamiento temporal de la misma.
Cada microservicio de XAIX: XAIX API, XAIX SPI Connect, XAIX Plugin, XAIX Admin, puede escalar horizontalmente agregando más nodos (contenedores, servidores) de cada tipo de manera transparente para toda la solución.
5. Cumplir con los demandantes plazos del BCP
El BCP puso plazos muy justos para toda la implementación. La primera gran prueba empezó en un proceso que denominaron CERTFICACIÓN el Lunes 23 de Mayo y se extendió por casi 3 semanas. De nuestras 10 implementaciones, las 10 pasaron con éxito el proceso.
Concluyendo
El SPI presenta un gran servicio para todos los paraguayos que vamos a poder hacer transferencias a toda hora. También una gran oportunidad para todos los comercios que probablemente van a empezar a adoptar con más formalidad y más fuerza este medio de cobros gratuito para sus clientes. Así mismo, una gran oportunidad para todo el ecosistema FINTECH del Paraguay que va a poder desarrollar nuevos productos y servicios que mejoren las experiencias de productos existentes.
Agradecemos públicamente a nuestros clientes por la confianza de siempre depositada y en
Roshka estamos felices de ser parte de esta revolución. Por la envergadura de nuestros clientes que nos eligieron para sus implementaciones, sabemos que
más de la mitad de todos los pagos instantáneos del Paraguay van a pasar por tecnología nuestra. Porque
La Vanguardia, es así.